1. 제목
- TRAFFIC: 논문에서 제안하는 모델명
- Recognizing Object: (=Object Recognition) 객체 인식.
즉, 어떤 input 안에 속해 있는 유의미한 object를 인식하여 분류, 명명 등의 output을 내뱉음 - Hierarchical Reference Frame: 계층적 구조.
얼굴 이미지를 예로 들자면,
input image > 얼굴 > 눈, 코, 입 귀 등 > 눈썹, 눈동자 혹은 입술 > 선 (line or edge) - Transformations: 변환 행렬
제목이 꽤 많은 내용을 내포하고 있는 논문이다. 제목의 단어들을 개념 단위로 구분해서 뜯어보자.
모델 명을 제외하고, <Recognizing Object>부터 살펴보자. 다르게 표현하면 object recognition으로 직역하면 “객체 인식”이다. Object Recognition은 Computer Vision 분야의분야의 주된 목적이자 목표로, 이미지 혹은 영상에서의 객체(사람, 자동차, 동물 등)를 말 그대로 “인식”하는 것을 말한다. “인식”은 다시 세분화되어, 단순히 “사람이다, 아니다”로 binary-classification “이진 분류”하는 방식과, “사람이다, 자동차이다”로 multi-classification “(세분화) 명명세분화)명명 혹은 다중 분류”하는 방식이 있다. 그리고 또 다른 인식 방법인 localization 객체의 “위치를 찾는” 방식이 있다. 이를 좀 더 깊게 들어가면, 이미지 혹은 영상 안에 어떤 객체들이 있는지, 어디에 있는지까지 detection “찾고 명명”할 뿐만 아니라, 이미지를 픽셀 단위로 낱낱이 segmentation “분해하고 분류 및 명명”까지 할 수도 있다. 본 논문에서는 이런 개념을 통틀어 사용하기 위해 task를 구체화하지 않고 <Object Recognition>이라는 말을 사용하였다.
다음으로 <Hierarchical Reference Frame>이다. 직역하면 “계층적 기준 구조”라는 뜻으로, object recognition을 How? 어떻게? 하겠다는 말인가, 라는 질문에 이미지 내의 계층적 구조를 이용하겠다는 대답이라고 할 수 있다. 이 단어는 논문을 읽어가면서 세부적으로 이해가 되는데, 간단히 개념을 먼저 잡고 가기 위해 얼굴 이미지의 예시를 들었다. 증명사진을 생각해 보자. 이미지 안에 얼굴(객체)이 있고, 얼굴 안에 눈, 코, 입(얼굴의 부분이자 더 아래 부분의 객체), 눈(객체) 안에 눈썹, 눈동자(눈의 부분이자 더 아래 부분의 객체), 눈썹(객체) 안에 선(line)이 있다. 예시와 같이 object(객체)-feature(부분)이 recursive(반복적으로)하고, 피라미드형으로 hierarchical(계층적으로) 되어 있어 <Hierarchical Frame>이다.
그렇다면 <Reference>란 어떤 의미일까? 계층적 구조인데, 참조 즉 “기준”이 되는 계층적 구조라는 뜻이다. 얼굴을 수직으로 따라 내려오면, 이마, 눈 두 개,코, 입이 있다. 사람 마다 이 계층적 구조가 다른가? 아니다. 이마, 코, 눈 두개, 입인 사람은 없다. 그래서 <Reference> “기준”이 되는 <Hierarchical Frame> 계층적계층적 구조를 통해 <object recognition>을 하겠다는 뜻이다.
이제 마지막으로 <Transformations>이다. “변환”이라는 뜻을 가진 이 단어는, <Hierarchical Reference Frame>을 어떻게 알아내겠다는 거지? 에 대한 답을 가지고 있다. 바로 Transformation Matrix를 통해서다. 다시 얼굴을 예로 들어보자.

얼굴이 비스듬히 있는 것, 혹은 옆으로 있는 것, 등의 증명사진에서의 변형이 위 사진처럼 변환 행렬을 통해 표현이 가능한 것이다.
이제 제목을 요약하면, 본 논문은 TRAFFIC이란 모델을 소개하고자 하는데, 이는 object recognition을 목표로 하는 모델이고, 이 목표는 Transformations Matrix를 통한 Hierarchical Reference Frame을 학습함으로써 이루어진다는 뜻이다. 제목에 제안하고자 하는 내용과 이루고자 하는 목표, 그를 위한 방법까지 모두 제시되어 있다.
2. Abstract
본 모델은 orientation(방향), position(위치), scale(크기)에 independent(상관 없이)하게 2D(x, y축)의 unsegmented image에서 object(객체)를 recognize(인식) 하는 것을 목표로 한다. TRAFFIC은 object와 feature사이 structural(구조적) relationship을 viewpoint-invariant transformation을 encoding 함으로써 표현한다. 이 때이때, transformation matrix는 feature의 기준 frame에서 object로 연결되는 network의 weight를 통해 학습된다. Transformation의 hierarchy를 이용함으로써 각 계층의 feature와 mapping 되는 연속적 layer는 complexity가 증가하고, 이에 따라 network는 여러 객체를 병렬적으로 인식할 수 있다.
3. Introduction
본 논문은 다음과 같은 말로 시작한다.
A key goal of machine vision is to recognize familiar objects in an unsegmented image, independent of their orientation, position, and scale.
비전의 가장 중요한 목표는, unsegmented image, 즉 pixelwise 하게 분석 및 분류되지 않은 raw 한 이미지가 주어졌을 때, 유사한 객체를 인식하는 것이라는 뜻이다. 다만 여기서 저자는 조건을 부치는데, 바로 orientation, position, scale에 independent 해야 한다는 것이다.
그리고 이 문제가 어려운 이유를 이야기한다.
The complexity of object recognition stems primarily from the difficult search required to find the correspondence between features of candidate objects and image features.
이미지 상에는 수많은 feature들이 있고, 모델이 최종적으로 인식하고자 하는 object가 마구 혼재되어 있다. 어떤 feature는 object와 전혀 상관이 없는 것일 것이고 (예를 들면 noise), 어떤 feature는 object recognition에 매우 중요한 것일 수 있다. 이런 복잡한 상황은 real-world data일 때 더욱 심하게 나타난다. (real-world 데이터는 정제되어 있지 않고, segmented 된된 경우도 거의 없기 때문이다.)
따라서 본 논문은 이 complexity problem을 해결하고자 TRAFFIC(transforming feature instances) 모델을모델을 제안한다. 본 모델은 세 가지 bullet-point를 내세운다.
- Build constraints on the spatial relationships between features of an object directly into architecture of a connectionist network
- Embed this construction into a hierarchical architecture
- Discover the critical spatial relationships among features in various poses
모델은 첫 번째 point를 통해, 이미지의 수많은 feature 중 object와 연관성이 높을 것 같은 feature를 object와 matching 하고,두 번째 point에서 첫 번째 point를 직접적으로 embedding 함으로써 unsegmented, non-normalized images, wide range candidate objects에 대한 문제를 직접적으로 해결한다. 그리고 마지막 point를 통해 다양한 위치의 object-feature의 spatial 관계를 학습하게 된다.
4. Model Highlights
A. Encoding Structural Relations
The first key aspect of TRAFFIC concerns its encoding and use of the fixed spatial relations between a rigid object and each of its component features.
Rigid는 유사어로 inflexible, 즉 ‘융통성이 없는’을 뜻한다. 일단 rigid 한 object와 그 feature 사이의 공간적 관계를 encoding 해야 한다는 뜻이다. 만약 각 feature마다 고유한 기준 frame이 있다면, 그 object와 feature는 <fixed viewpoint-independent transformation>을 가지게 된다. 그리고 이 transformation을 통해 object의 reference frame을 predict “예측”까지 할 수 있게 된다. 즉, 얼굴과 그 내부의 세부 개체들의 관계를 잘 학습해 놓기만 한다면, 어떠한 방향의 시선에서 건 상관없이 object-feature의 공간적 관계를 통해 예측하여 얼굴이라는 것을 인식할 수 있다는 말이다. 다만, transformation을 통해 예측이 가능하기 위해서는, 같은 object와 연관된 모든 feature가 identical reference frame을 가져야 한다.
Reference Frame Transformation은 network의 연결을 통해 matrix multiplication으로 나타낼 수 있다.
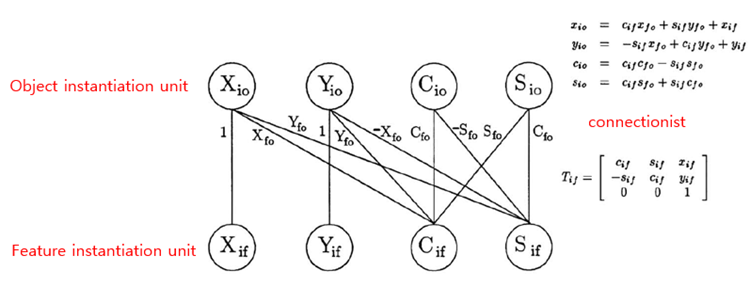
한 layer는 특정 feature를 표현하는 unit들로 구성되어 있고, 그 위의 layer는 object를 표현하는 unit들로 구성되어 있다. 그리고 한 feature는 총 4개의 instantiation unit을 갖는다. 각각 (x, y)-position, orientation, scale이다. 이 때, 변환 행렬은 cosine, sine, x-y position으로 구성된다.

변환 행렬은 다음과 같이 구성되며, Tio를 구함으로써 최종적으로 object recognition의 목표에 달성하게 된다. 여기서 한 가지 주의할 점은 Tfo라는 역방향 변환이 있다는 것이다. 이는 추후에 읽게 될 논문에서 <Routing>이 등장하는 계기가 된다. 일단 TRAFFIC모델에서는 Tfo가 단순 layer사이 weight로서 학습되는 값이기 때문에, 상관이 없다. 다시 말해, Tif, Tio는 image와 object/feature사이의 관계이기 때문에 값으로 구할 수 있으므로, 그 사이를 연결해 주는 행렬의 weight만 구하면 되는 것이다. 그리고 이 고정된 변환 행렬을 통해, 일정한 예측을 할 수 있다.
B. Feature Abstraction Hierarchy
A번이 traffic모델의 가장 핵심적인 부분이었다면, B, C는 A를 보완하기 위한 method이다.
A방법으로 단순히 학습하기에는 치명적 문제가 있다.
얼굴을 예로 들면, “얼굴”이라는 것을 학습하기 위해 input을 눈썹으로 넣는다면 단순 선으로 인식하여 얼굴과 매칭 하기 어려울 것이고, 당장 눈부터 넣으면 선을 학습하지 않아 문제가 된다.
이를 해결하기 위한 방법이 recursive 하게 hierarchical 한 feature-object layer를 쌓는 것이다. 그러면 순서대로, 선 혹은 모서리 -> 눈썹, 눈동자 -> 눈 -> 얼굴로 feature-object관계를 학습하면서 문제가 해결된다.
C. Forming Object Hypotheses
마지막으로, feature-object관계를 recursive 하게 순차적으로 학습할 때, 얼굴 속에 만약 “눈”이 하나 없는 얼굴 이미지면 어떡하지?, 하는 문제에 대한 해결책을 제시한다.
<Object Confidence>라는 additional unit을 통해 object가 image에 존재하는가에 대한 likelihood값을 통해, 눈이 하나 없으면 object confidence가 낮아짐으로써 얼굴이 아니게 된다.
TRAFFIC이 Object Confidence와 같이 작동하는 방식은 다음과 같다.
- 각 feature별로 object의 reference frame을 예측한다.
- TRAFFIC이 single vector object instantiation-parameter를 averaging 하고 object confidence 값을 weighted 한다.
- Receptive field의 object는 feature instance에 굉장히 sensitive 하여, low variance prediction value가 highly self-consistent object instantiation이 된다.
- 즉 output level layer에서는 object confidence가 object가 존재하는가, 하지 않는가를 likelihood값으로 나타내고, instantiation unit이 그 pose를 나타낸다.
5. Conclusion & Summary
- TRAFFIC모델은 CapsuleNet의 모체가 되는 아이디어로서 feature-object 간의 관계 학습을 통해, 위치, 각도, 크기에 무관하게 object recognition을 시도한다.
- 특히, 고정된 변환 행렬의 값을 찾음으로써, feature-object 관계를 embedding 하려는 시도가 기존 CNN과의 차별점이다.
참고자료